Investigating interlanguage stages
Vowel phonemic distinctions among French speakers of English
Adrien Méli and Nicolas Ballier
Corpus and methodology
Corpus
- 30 recordings of 10 female students following a course in English at Université Paris-Diderot
- each student recorded three times at one-year intervals (as part of the LONGDALE Project)
- spontaneous speech produced in interviews with native speakers
Methodology
- Goal: investigate phonemic categorization (esp. vowels); is it idiosyncratic or predictable? Does it evolve? How?
- Data: collecting as much information (formants, syllabic structures, stress) as possible on each vowel
- Softwares used: Audacity, PRAAT, SPPAS, R (+ some Python scripts)
Workflow
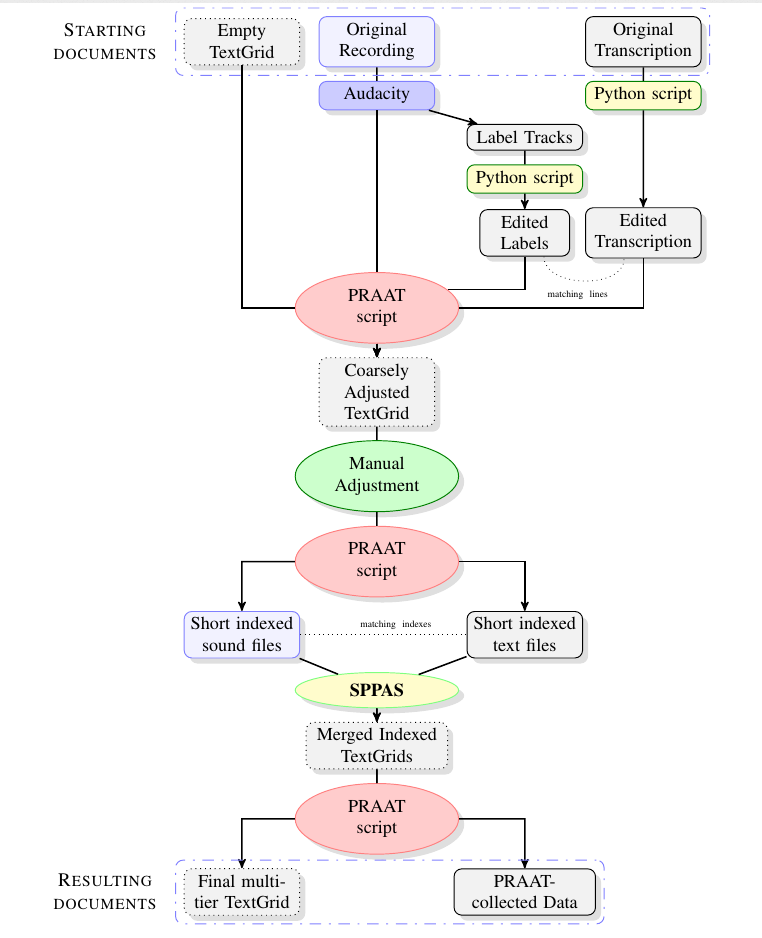
Outputs
- a spreadsheet:
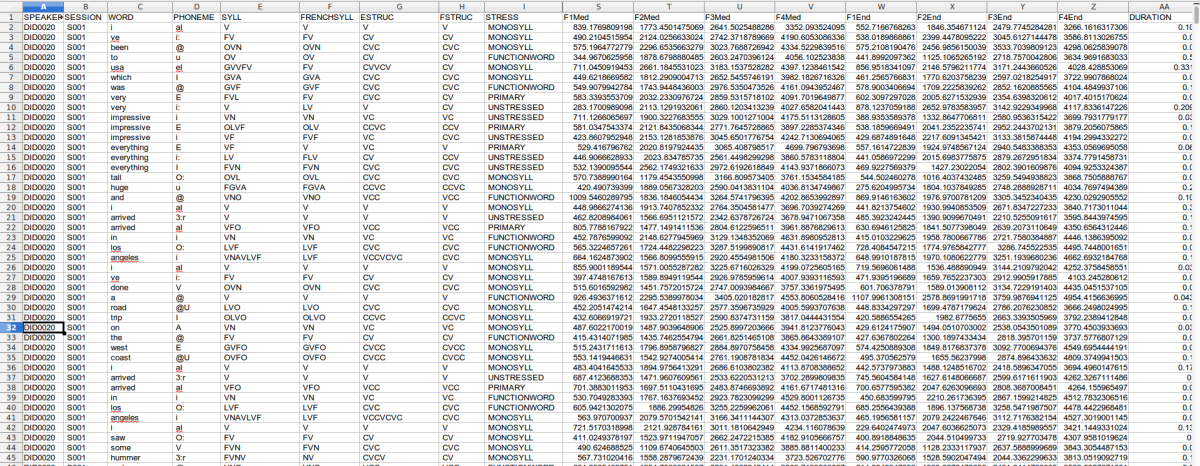
- so far: 31,205 tokens for the 10 students.
Outputs
- aligned, multi-tier TextGrids:
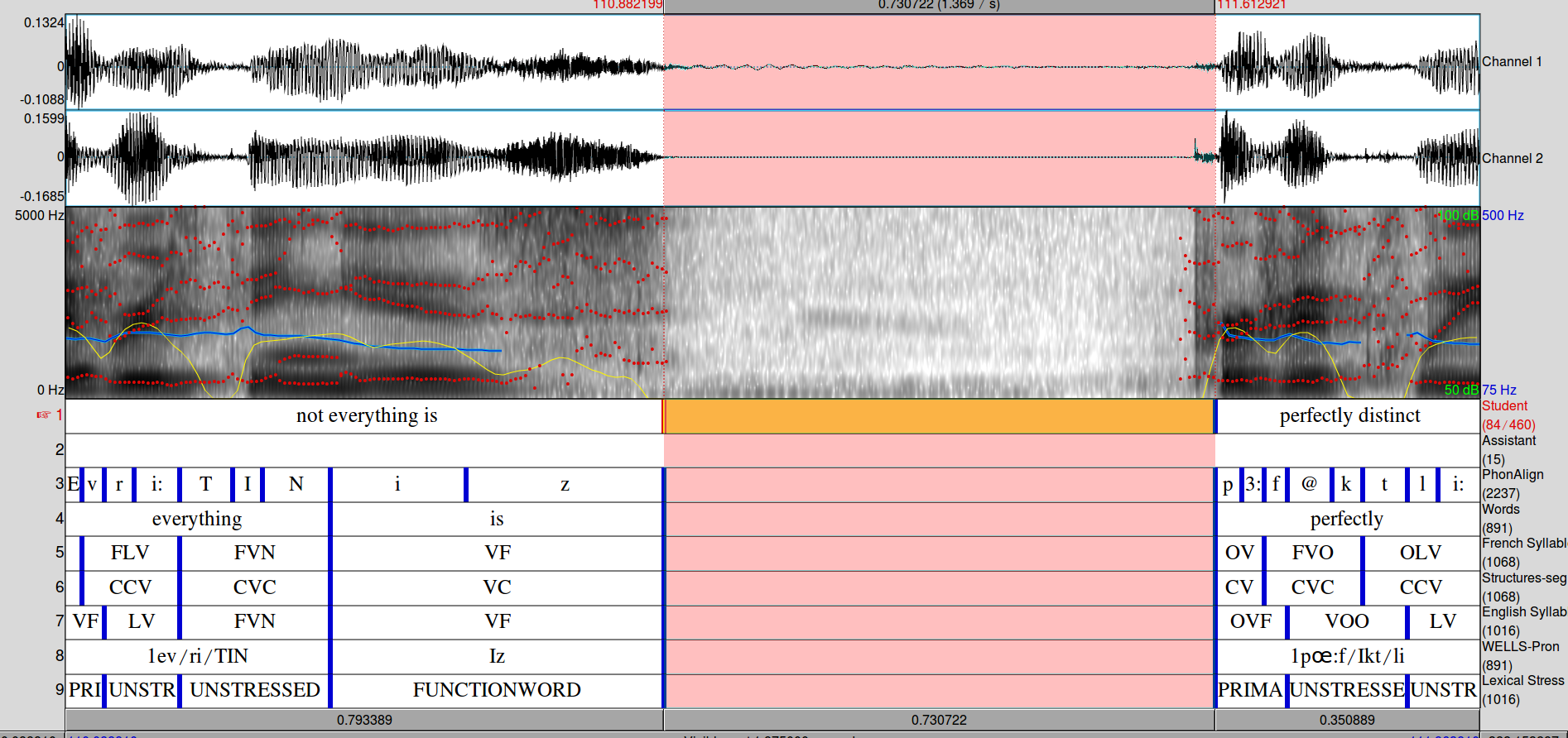
- Having one single TextGrid makes further research (e.g. on fricatives, aspiration, syllabic cues, etc.) easier.
A critical look
Pros
- language in vivo: true level of acquisition can be assessed. Pronunciation is not the primary focus of the speakers: conveying meaning, as in 'true' language, is.
- automatization enables the collection of a substantial number of formants.
A critical look
Challenges
- a fundamentally skewed corpus: varying total numbers of phonemes (due to context, function words, word frequency, Zipf's law, etc.).
- automatization: accuracy of formants extractions via PRAAT scripts?
- theory: different phonologies (natives' and learners'). Chosen categorization is a bias in itself (SPPAS uses a US pronunciation dictionary).
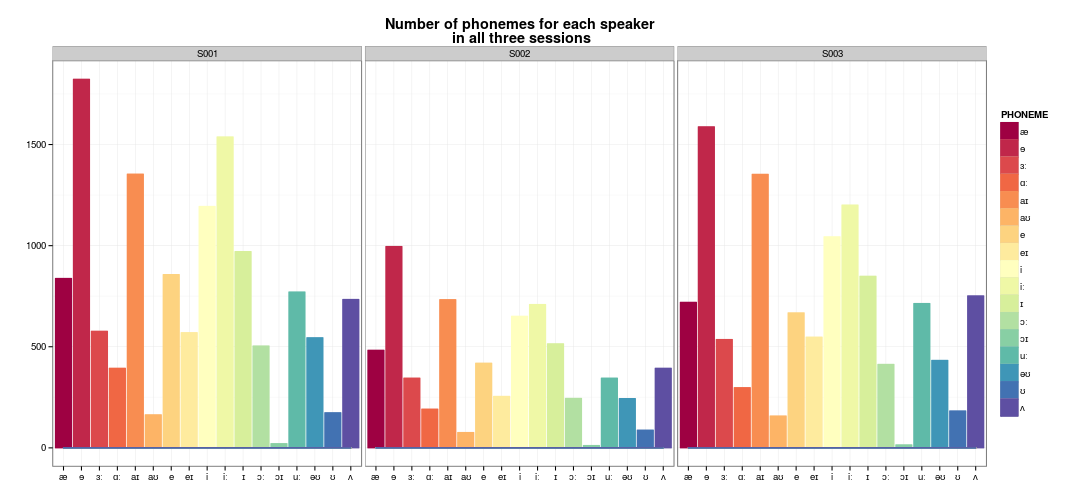
Number of phonemes (monophthongs)
| S001 | S002 | S003 | Total | |
|---|---|---|---|---|
| æ | 838 | 483 | 720 | 2041 |
| ɘ | 1823 | 996 | 1588 | 4407 |
| ɜː | 577 | 345 | 536 | 1458 |
| ɑː | 394 | 192 | 298 | 884 |
| e | 857 | 419 | 668 | 1944 |
| i | 1194 | 651 | 1044 | 2889 |
| iː | 1538 | 709 | 1201 | 3448 |
| ɪ | 971 | 515 | 849 | 2335 |
| ɔː | 504 | 245 | 413 | 1162 |
| uː | 771 | 345 | 714 | 1830 |
| ʊ | 174 | 88 | 183 | 445 |
| ʌ | 734 | 394 | 752 | 1880 |
| Total | 10375 | 5382 | 8966 | 24723 |
Number of phonemes (diphthongs)
| S001 | S002 | S003 | Total | |
|---|---|---|---|---|
| aɪ | 1354 | 733 | 1353 | 3440 |
| aʊ | 164 | 76 | 158 | 398 |
| eɪ | 570 | 255 | 548 | 1373 |
| ɔɪ | 21 | 12 | 15 | 48 |
| əʊ | 545 | 244 | 433 | 1222 |
| Total | 2654 | 1320 | 2507 | 6481 |
Monophthongs frequencies
Per-session number of occurrences of each monophthong
Number of phonemes
Per session
Overview of the results
Coarse assessment
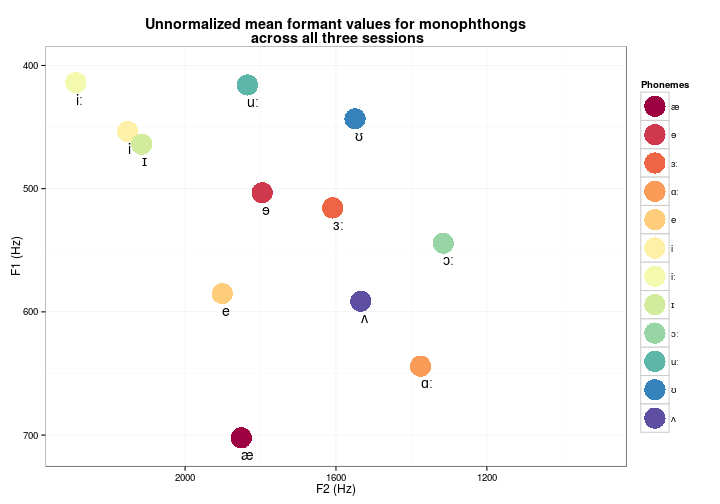
- What vowel diagram do we obtain if we use the mean values of the F1/F2 formants for each phoneme?
Vowel diagram
Mean F1/F2 (Hz) values
Phonemic evolution over three years
Means of unnormalized formant values
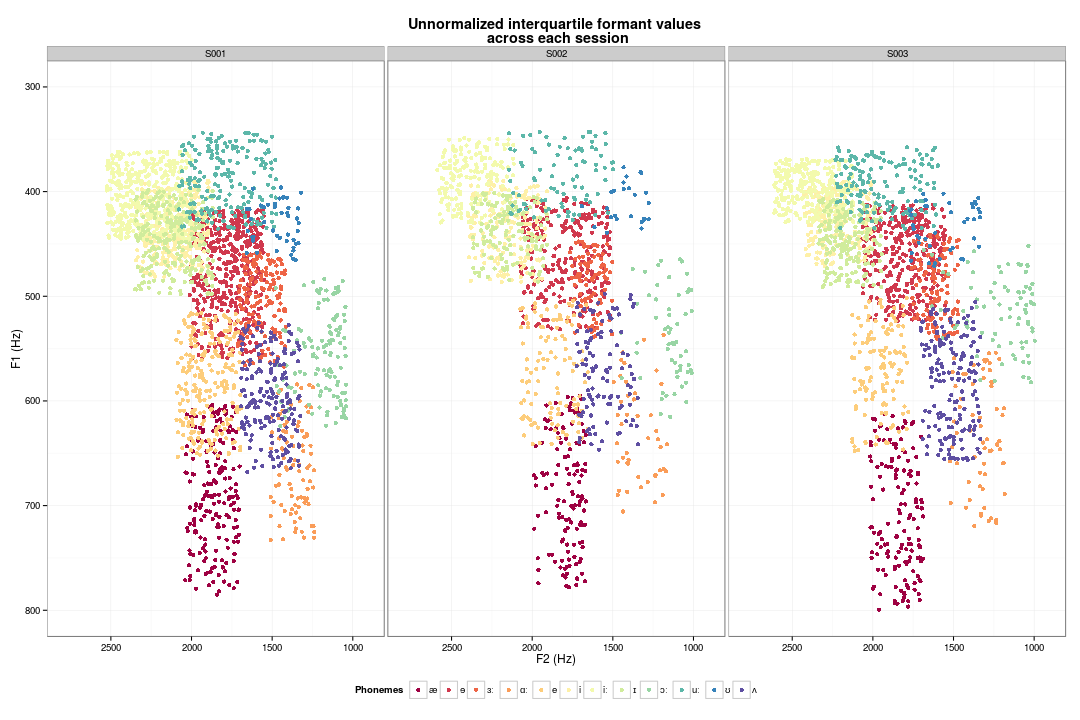
Using interquartile values
Justifications:
- Reduction of errors due to automatic extraction
- Mispronunciations (e.g. of rarer words) do not reflect phonological knowledge
- Substantial Standard deviations :
Standard deviations
Per monophthong for F1
Standard deviations
Per monophthong for F2
Standard deviations
Relationship with frequency of occurrences (F1)
Standard deviations
Relationship with frequency of occurrences (F2)
Interquartile values
Unnormalized values in Hz: distribution
Interquartile values
Means of unnormalized formant values
Normalization
Using Lobanov:
- Bark-transformation
- z-score
- using native values from Ferragne and Pellegrino (2010)
- regardless of unequal frequences...
- dataframes created using R package phonTools
Bark z-score formants
Means of normalized interquartile values
A closer look
Interlanguage of problematic phonemes
How do they evolve?
| French | English |
|---|---|
| i | ɪ - iː |
| u | ʊ - uː |
| ɔ | ɔː - ɑ |
Evolution of problematic phonemes (in Hz)
Discussion
- quartiles: phonetic or statistic truth?
- normalization issues: artificial requirements vs. spontaneous speech.
- token effects/frequency effects
- formulaic "islands of reliability":