The counts of phonemes are unevenly distributed
(n = 17,189 for the 12 four-session speakers)
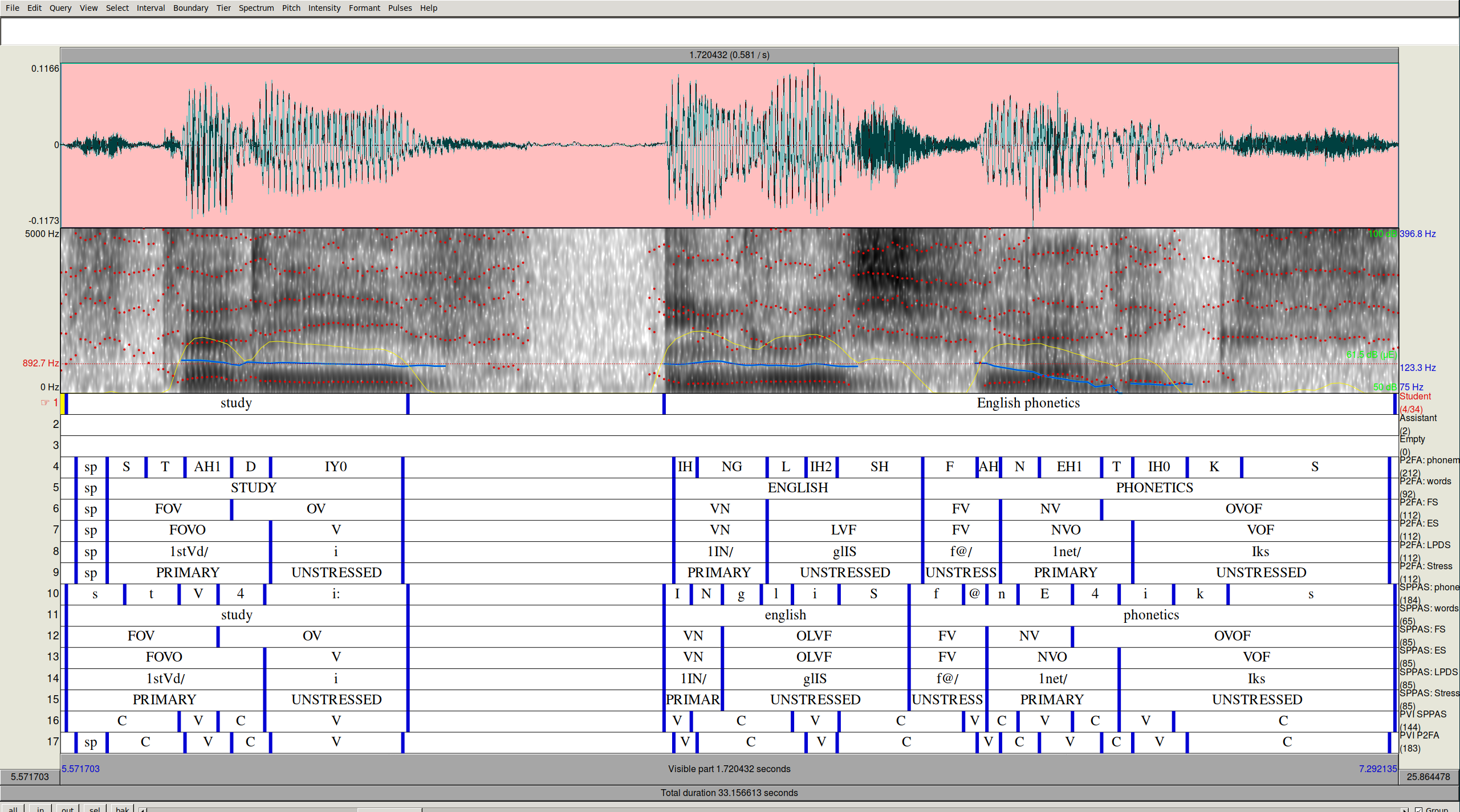
Does the analysis depend on how the data is processed?
A look at the mean Euclidean distances between female native and learner values in the F1/F2 vocalic space
For mid-temporal values, the differences between raw and BDM-normalized values are minimal
Inter-speaker comparisons: A trend for /ɪ/?
When taking Peterson & Barney as reference point the distances are greater than with the NSS values
When taking Peterson & Barney as reference point /ɪ/ and /iː/ seem closer to native values
Reminder: Discrete Cosine Transform
(x-axis: percentage of the vowel’s duration; y-axis: Bark)

Discrete Cosine Transforms: K0 Inter-phoneme differences
Discrete Cosine Transforms: K0 Inter-speaker differences
Discrete Cosine Transforms: K1 Inter-phoneme differences
Discrete Cosine Transforms: K1 Inter-speaker differences
A tentative conclusion
Regardless of how the data is processed, /ʊ/ and /uː/ feature more instability, and their formant values are further from native values than those of /ɪ/ and /iː/. The ℋ0 can be rejected.